"Reinforcing" policy learning with a fuzzy-logic-based reward shaping
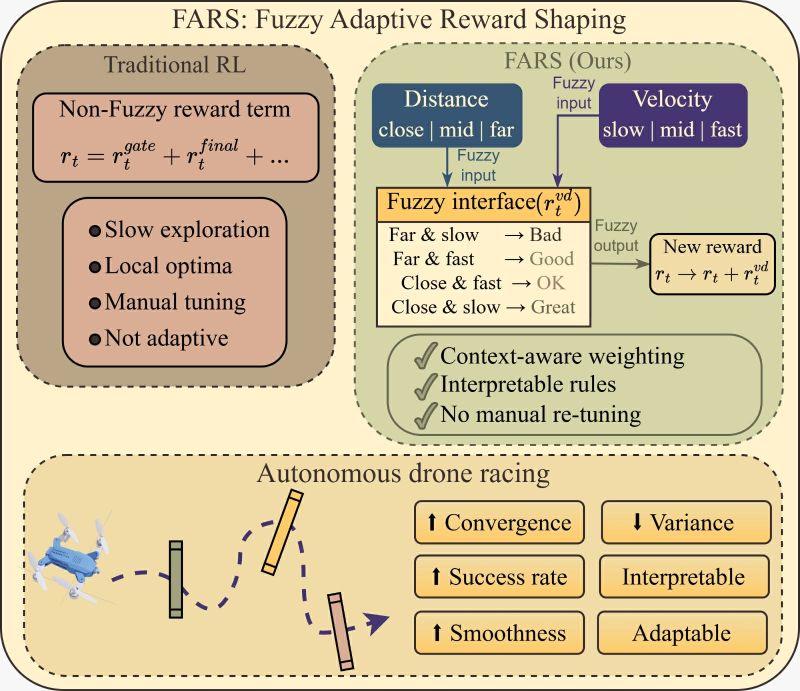
Accepted at IEEE WCCI 2026, our work "Fuzzy Logic Theory-based Adaptive Reward Shaping for Robust Reinforcement Learning (FARS)" explores how fuzzy-logic-based reward shaping can improve reinforcement learning in complex, real-world scenarios with high-dimensional states and long horizons.
By integrating human intuition into reward design, our approach:
- Stabilizes learning
- Reduces sensitivity to hyperparameters
- Enables smoother transitions between fast and precise control
Tested on autonomous drone racing tasks, we observe faster convergence, more consistent performance, and up to ~5% improvement in success rates compared to standard reward formulations.
Stay tuned for paper release!


{kind=link}