How do we stabilize learning in differentiable simulation?
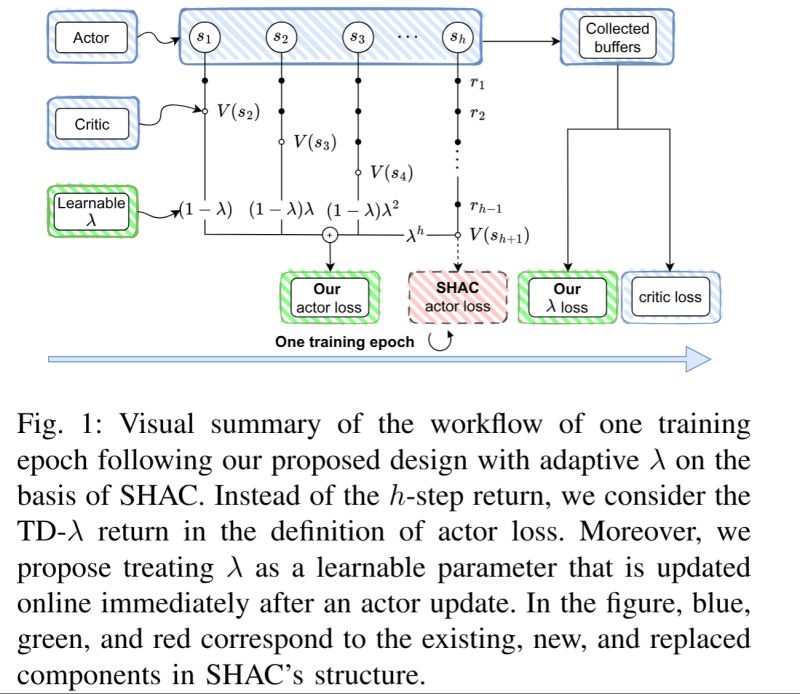
Our new work, accepted at IEEE WCCI 2026, “ARE: Adaptive TD-λ Return Estimation for Learning Control in Differentiable Simulation,” proposes to tackle this challenge by replacing traditional k-step returns with TD-λ returns in first-order model-based reinforcement learning (FO-MBRL) algorithms.
The result? A smoother learning landscape, reduced gradient variance, and significantly more stable training.
Experiments show 50–100% improvements in episodic rewards over Short-Horizon Actor Critic (SHAC) and Soft-Analytic Policy Gradient (SAPO) on challenging locomotion tasks.
Paper coming soon—stay tuned!


{kind=link}